Optimización del Rendimiento en Shiny
Técnicas y Mejores Prácticas
Material
Estructura del Taller (3 horas)
- Introducción
- Ciclo de optimización: Ejercicio 1 - Benchmarking
- Profiling: Ejercicio 2
- Optimización - Data: Ejercicio 3
- Optimización - Shiny: Ejercicio 4
- Optimización - Async: Ejercicio 5
- Temas avanzados
- Preguntas
Introducción
Appsilon

We are hiring!
Para ver más posiciones: https://www.appsilon.com/careers
Quién soy
- Politólogo y ahora R shiny developer
- De Lima, Perú
- Contacto:
¿Quiénes son ustedes?
- Compartir en el chat:
- Nombre
- De dónde son y qué hora es en su ciudad
- Background profesional (brevísimo)
- 3 paquetes de R favoritos (si son de nicho, mejor)
Ciclo de Optimización
Primero lo primero
¿Qué es una computadora? La interacción de 3 componentes principales

¿Qué es optimizar?

¡Depende de la necesidad!
En general, pensemos en tiempo (CPU) o espacio (memory/storage). El dinero es un eje secreto.
El ciclo graficado

https://www.appsilon.com/post/optimize-shiny-app-performance
A saber en cada etapa
- Benchmarking: ¿Performa como esperamos?
- Profilling: ¿Dónde están los cuellos de botella?
- Estimación/Recomendación: ¿Qué puedo hacer?
- Optimización: Tomar decisión e implementar
Tipos de benchmarking
- Manual
- Avanzado (shinyloadtest):
Ejercicio 1 - Benchmarking

Prueba la app y anota cuánto tiempo te toma ver la información para:
3 ciudades diferentes
3 edades máximas diferentes
Enlace: https://01933b4a-2e76-51f9-79f4-629808c48a59.share.connect.posit.cloud/
Profiling
Profiling - Herramientas en R
El profiling es una técnica utilizada para identificar cuellos de botella en el rendimiento de tu código:
{profvis}
Es una herramienta interactiva que proporciona una visualización detallada del tiempo de ejecución de tu código.
- Instalación:
- Uso básico:
shiny.tictoc
Una herramienta que usa Javascript para calcular el tiempo que toman las acciones en la app, desde el punto de vista del navegador.
Es super fácil de añadir a una app.
- Si no saben añadir JS: Packaging Javscript code for Shiny
Ejecutar cualquiera de estas operaciones en la consola de Javascript.
// Print out all measurements
showAllMeasurements()
// To download all measurements as a CSV file
exportMeasurements()
// To print out summarised measurements (slowest rendering output, slowest server computation)
showSummarisedMeasurements()
// To export an html file that visualizes measurements on a timeline
await exportHtmlReport()Muchos navegadores cuentan con herramientas de desarrollador donde puedes encontrar una mientras tu app está corriendo.
Usando profvis
Ubicar la herramienta en Rstudio

La consola de R mostrará el botón “Stop profiling”. Esto significa que el profiler está activado.

Corre tu shiny app e interactúa con ella. Luego, puedes detener la app y el profiler.
El panel de edición de Rstudio te mostrará una nueva vista.

La parte superior hace profiling de cada línea de código, la parte inferior muestra un FlameGraph, que indica el tiempo requerido por cada operación.
También puede accederse a la pestaña “Data”.

Esta indica cuánto tiempo y memoria se ha requerido por cada operación. Nos da un resumen de la medición.
Para una revisión más exhaustiva del uso de {profvis}, puedes consultar la documentación oficial:
- Ejemplos: https://profvis.r-lib.org/articles/rstudio.html
- Integración con RStudio: https://profvis.r-lib.org/articles/rstudio.html
Ejercicio 2 - Profiling
Realiza el profiling del archivo “app.R”.
- Interpreta los resultados
- ¿Cuáles son los puntos más críticos?
Toma en cuenta que estás probando esto para un solo usuario.
Optimización - Data
- Usar opciones más rápidas para cargar datos
- Usar formatos de archivo más eficientes
- Pre-procesar los cálculos
- Usar bases de datos. Puede requerir aprender SQL.
¡Puedes combinar todo!
Cargar datos más rápido
- data.table::fread()
- vroom::vroom()
- readr::read_csv()
Ejemplo
NO ejecutar durante el workshop porque toma tiempo en correr
suppressMessages(
microbenchmark::microbenchmark(
read.csv = read.csv("data/personal.csv"),
read_csv = readr::read_csv("data/personal.csv"),
vroom = vroom::vroom("data/personal.csv"),
fread = data.table::fread("data/personal.csv")
)
)
#> Unit: milliseconds
#> expr min lq mean median uq max neval
#> read.csv 1891.3824 2007.2517 2113.5217 2082.6016 2232.7825 2442.6901 100
#> read_csv 721.9287 820.4181 873.4603 866.7321 897.3488 1165.5929 100
#> vroom 176.7522 189.8111 205.2099 197.9027 206.2619 495.2784 100
#> fread 291.9581 370.8261 410.3995 398.9489 439.7827 638.0363 100Formatos de datos eficientes:
- Parquet (via {arrow})
- Feather (compatibilidad con Python)
- fst
- RDS (nativo de R)
Ejemplo
NO ejecutar durante el workshop porque toma tiempo en correr
suppressMessages(
microbenchmark::microbenchmark(
read.csv = read.csv("data/personal.csv"),
fst = fst::read_fst("data/personal.fst"),
parquet = arrow::read_parquet("data/personal.parquet"),
rds = readRDS("data/personal.rds")
)
)
#> Unit: milliseconds
#> expr min lq mean median uq max neval
#> read.csv 1911.2919 2075.26525 2514.29114 2308.57325 2658.03690 4130.748 100
#> fst 201.1500 267.85160 339.73881 308.24680 357.19565 834.646 100
#> parquet 64.5013 67.29655 84.48485 70.70505 87.81995 405.147 100
#> rds 558.5518 644.32460 782.37898 695.07300 860.85075 1379.519 100Pre-procesar cálculos
- Filtrado previo: Menos tamaño
- Transformación o agregación previa: Menos tiempo
- Uso de índices: Búsqueda rápida
Es, en esencia, caching. Personalmente, mi estrategia favorita.
Difícil de usar si se requiere calcular en vivo, real-time (stock exchange, streaming data), o la data no puede ser guardada en cualquier lugar (seguridad, privacidad).
Sin pre-procesamiento
Con pre-procesamiento
Bases de Datos relacionales
- Escalabilidad: Las bases de datos pueden manejar grandes volúmenes de datos de manera eficiente.
- Consultas Rápidas: Permiten realizar consultas complejas de manera rápida.
- Persistencia: Los datos se almacenan de manera persistente, lo que permite su recuperación en cualquier momento.
Algunos ejemplos notables son SQLite, MySQL, PostgreSQL, DuckDB.
freeCodeCamp tiene un buen curso para principiantes.
Ejercicio 3 - Data
Implementa una estrategia de optimización
Optimización - Shiny
Cuando una app arranca

Del lado de shiny, optimizar consiste básicamente en hacer que la app (en realidad, el procesador) haga el menor trabajo posible.
Reducir reactividad
server <- function(input, output, session) {
output$table <- renderTable({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
})
output$histogram <- renderPlot({
survey |>
filter(region == input$region) |>
filter(age <= input$age) |>
ggplot(aes(temps_trajet_en_heures)) +
geom_histogram(bins = 20) +
theme_light()
})
}reactive() al rescate
server <- function(input, output, session) {
filtered <- reactive({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
})
output$table <- renderTable({
filtered()
})
output$histogram <- renderPlot({
filtered() |>
ggplot(aes(temps_trajet_en_heures)) +
geom_histogram(bins = 20) +
theme_light()
})
}Controlar reactividad
Puedes encadenar bindEvent() a un reactive() u observe().
ui <- page_sidebar(
sidebar = sidebar(
selectInput(inputId = "region", ...),
sliderInput(inputId = "age", ...),
actionButton(inputId = "compute", label = "Calcular")
),
...
)
server <- function(input, output, session) {
filtered <- reactive({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
}) |>
bindEvent(input$compute, ignoreNULL = FALSE)
}Ahora filtered() solo se actualizará cuando haya interacción con input$compute.
Estrategias de Caché
bindCache() nos permite guardar cómputos al vuelo en base a ciertas keys.
Cuando una combinación vuelva a aparecer, se leerá el valor en lugar de recalcularlo.
- Niveles de caché:
- Nivel aplicación:
cache = "app"(default) - Nivel sesión:
cache = "session" - Personalizado:
cache object + opciones
Por defecto, se usará un máximo de 200 Mb de caché.
Comunicación servidor - navegador
- Enviar datos desde el servidor hacia el navegador toma tiempo.
- Datos grandes -> mayor tiempo de envío.
- Conexión lenta -> mayor tiempo de envío
- Igualmente, si los datos son grandes, al navegador le cuesta más leerlos y mostrarlos al usuario. Puede que la PC del usuario sea una tostadora!
- ¿Qué hacer?
- Reducir frecuencia de envíos (
bindEvent()) - Reducir tamaño de envíos
- Mandar lo mismo pero en partes más pequeñas (server-side processing o streaming)
- Reducir frecuencia de envíos (
Reducir tamaño de envíos
Es posible delegar ciertos cálculos al navegador. Por ejemplo, renderizar un gráfico con {plotly} en lugar de {ggplot2}.
Con ello, se manda la “receta” del gráfico en lugar del gráfico mismo. Al recibir la receta, el navegador se encarga de renderizarla.
Estas funciones traducen sintaxis de ggplot2 a sintaxis de plotly.js de manera bastante eficiente. Tiene soporte para muchos tipos de gráficos.

Pero no te confíes, en muchos casos, el código va a necesitar retoques. Especialmente al usar extensiones de ggplot2.
Otros paquetes similares:
- ggiraph
- echarts4r
- highcharter
- r2d3
- shiny.gosling (genomics, by Appsilon)
Server-side processing
En el caso de las tablas, el server-side processing permite paginar el resultado y enviar al navegador solo la página que está siendo mostrada en el momento.
El paquete {DT} es una opción solida.
Otra opcion:
{reactable}en conjunto con{reactable.extras}(by Appsilon).
Ejercicio 4 - Shiny
Implementa alguna de las optimizaciones mencionadas.
Optimización - Async
Programación síncrona
- Las tareas se ejecutan secuencialmente
- Es fácil de entender e implementa

Ejemplo: Una cocina con una hornilla. Si empecé a freir pollo, no puedo freir nada hasta terminar de freir el pollo.
Proramación asíncrona
- Las tareas pueden iniciar y ejecutarse independientemente
- Mientras se procesa una tarea, otras pueden ser iniciadas o completadas.

Ejemplo: Una cocina con múltiples hornillas. Si empecé a freir pollo en una hornilla, puedo freir otra cosa en una hornilla diferente.
Hornilla == Proceso en la PC
Cuidado
A más hornillas, también es más fácil quemar la comida!
Posibles complicaciones
- El código se hace más dificil de entender
- Sin adecuado control, pueden sobreescribir sus resultados
- Lógica circular. Proceso A espera a Proceso B, quien espera a Proceso A
- Incrementa la dificultad para hacer debugging porque los errores ocurren en otro lado
- Mayor consumo de energía
Beneficios
- Operaciones largas no bloquean a otras operaciones
- Flexibilidad: mi sistema se adapta a retrasos inesperados
- La aplicación se mantiene responsiva, no se “cuelga”
- Uso eficiente de recursos. “Pagué por 8 procesadores y voy a usar 8 procesadores”.
- Escalabilidad a otro nivel
Casos de uso
- Operaciones I/O:
- Query a bases de datos
- Solicitudes a APIs
- Cálculos intensivos
¿Qué necesito?
- CPU con varios núcleos/hilos.
- Paquetes:
- {promises}
- {future}
- ExtendedTask (Shiny 1.8.1+)
Nota
ExtendedTask es un recurso bastante nuevo. También es posible usar solo future() o future_promise() dentro de un reactive para lograr un efecto similar, aunque con menos ventajas.
Setup inicial
Esto le dice al proceso que corre la app que los futures creados se resuelvan en sesiones paralelas.
Procedimiento
- Crear un objeto
ExtendedTask. - Hacer bind a un task button
- Invocar la tarea
- Recuperar los resultados
Punto de partida - UI
Modificaciones - UI
Cambiamos el actionButton() por bslib::input_task_button(). Este botón tendrá un comportamiento especial.
Punto de partida - Server
Modificaciones - Server
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
future_promise({
p_survey |>
dplyr::filter(region == p_region) |>
dplyr::filter(age <= p_age)
})
}) |>
bind_task_button("compute")
observe(filter_task$invoke(survey, input$region, input$age)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}Modificaciones - Server
Paso 1: Se creó un ExtendedTask que envuelve a una función.
Dentro de la función, tenemos la lógica de nuestro cálculo envuelta en un future_promise(). La función asume una sesión en blanco.
Modificaciones - Server
Paso 2: Se hizo bind a un task button
Nota
bind_task_button() requiere el mismo id que input_task_button(). bindEvent() acepta cualquier reactive.
Modificaciones - Server
Paso 3: Invocar la tarea con ExtendedTask$invoke().
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
...
}) |>
bind_task_button("compute")
observe(filter_task$invoke(survey, input$region, input$age)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}Se le provee la data necesaria para trabajar. Tomar en cuenta que invoke() no tiene valor de retorno (es un side-effect).
Modificaciones - Server
Paso 4: Recuperar los resultados con ExtendedTask$result().
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(...) {
...
}) |>
bind_task_button("compute")
observe(filter_task$invoke(...)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}result() se comporta como cualquier reactive.
Modificaciones - Server
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
future_promise({
p_survey |>
dplyr::filter(region == p_region) |>
dplyr::filter(age <= p_age)
})
}) |>
bind_task_button("compute")
observe(filter_task$invoke(survey, input$region, input$age)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}¡Perdimos el cache! ExtendedTask() no es 100% compatible con las estrategias de caching vistas.
Ejercicio 5 - Async
- Implementa async para uno de los gráficos
- Discusión: ¿vale la pena?
Todo junto
Acá se desplegó la app con todas las mejoras vistas en los ejercicios. Además, survey utiliza la data completa, en lugar de una muestra por región.
Enlace: https://01933e23-3162-29f7-ec09-ce351b4b4615.share.connect.posit.cloud/-
Temas avanzados
Representando la complejidad
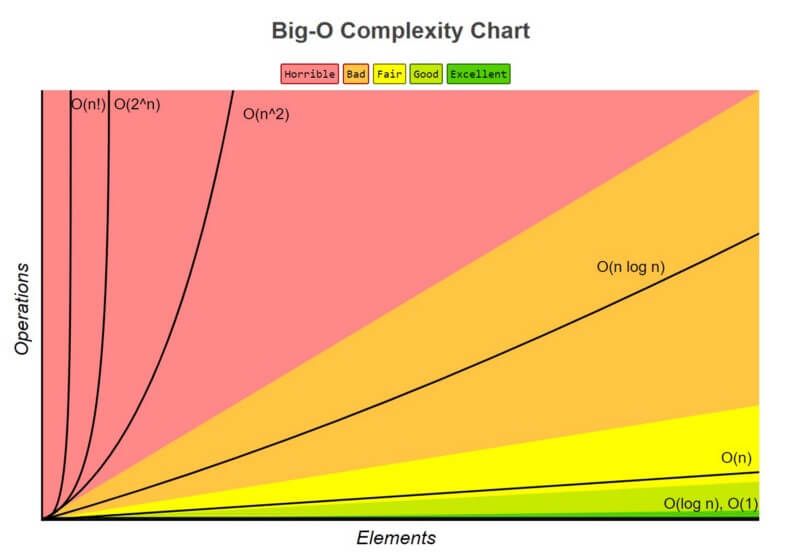
Entendiendo la complejidad
Algoritmos y estructuras de datos
Enfrentando la complejidad
¡{rhino} tiene todo esto!
Preguntas
¡Gracias!
- Web: https://www.samuelenrique.com
- Github: https://github.com/calderonsamuel
- Linkedin: https://www.linkedin.com/in/samuelcalderon/
![]()
LatinR: 2024-11-18